用Go STL查询DB引发的内存泄露
问题起因
这几天有一个 Go API service 经过定时监控发现占用的内存不断上涨,内存从初始的 70M 一直上升到超过 1G 直到吃光内存退出,基本上就可以断定是存在内存泄露的问题了,但是因为自带垃圾回收的语言出现内存泄露的情况较少,如果存在那一定是大问题,因此有了下文详细的排查过程,为日后处理此类问题积累经验。
分析排查
goroutine泄露
之前就有听说过一句名言:Go 中的内存泄露十有八九都是 goroutine 协程泄露,是否真的如此呢? 对 runtime.NumGoroutine() 的定时查询可以帮助我们进行判断,或者线上开启了 pprof 的话访问 /debug/pprof 就可以看到 goroutine 的数量,我使用了 expvar 来定时暴露协程的总数信息,在本地对线上数据定时进行抓取。
// server.go
// 将统计数据通过 expvar.Handler 暴露到 HTTP 服务中
mux := http.NewServeMux()
mux.Handle("/debug/vars", expvar.Handler())
// main.go
func sampleInterval() chan struct{} {
done := make(chan struct{})
go func() {
ticker := time.NewTicker(1 * time.Second)
numG := expvar.NewInt("runtime.goroutines")
defer ticker.Stop()
for {
select {
case <-ticker.C:
numG.Set(int64(runtime.NumGoroutine()))
case <-done:
return
}
}
}()
return done
}
// 本地运行
// curl http://host:port/debug/vars
{
"runtime.goroutines": 48
}
done chan 会被返回,以便我们关闭系统时可以进行优雅退出。通过一段时间的抓取和图表分析,发现并不是 goroutine 的泄露,如果是,那么可以访问 /debug/pprof/goroutine?debug=1 在线上查看每个 G 的状态,然后再来做进一步的分析,但显然通过排除法,这不是这次事故的问题所在。
长期持有引用
那么新的问题也就很自然地浮现出来:如果 G 的数量有上升然后总是能够自动回落,说明非常驻型的 G 都能够正常运行结束,G的阻塞等待导致迟迟无法退出造成的泄露是可以排除了,那么我们是否能够认为内存的泄露就完全与 G 无关了?答案是不能,因为我们不能确定 G 是否会导致我们的一些引用对象被一直持有,在标记 Mark 阶段的时候这些依然被持有的对象肯定是不能被垃圾回收的,但它因为某些原因一直被持有而且还伴随着新的内存分配,这是导致内存不断上涨的第二大元凶。
所以,随着问题落到了对象或者是对象群的内存分配上了,这个问题可以是某个 大的 slice 一直不断添加元素却一直在对象的生命周期中被引用,也可以是某对象中持有其他对象的指针,类似链表状的引用关系,如果这个引用链不断增长,那么同样也会造成内存的泄露。
使用 pprof 采样分析堆内存
通过获取 pprof heap profile,我们能够在线上直接生成当前堆内存分配的快照文件并通过 .pb.gz 压缩包的形式持久化到本地供我们作进一步的离线分析。
go tool pprof http://[domain]/debug/pprof/heap
使用命令行就能够将堆内存的快照以及各种统计数据都持久化到本地进行分析,进入到 pprof 交互式命令行。这边我直接在线上隔一段时间分别抓取了两次快照到本地来分析:
File: binary
Type: inuse_space
Time: Feb 27, 2020 at 12:06pm (CST)
(pprof) top
Showing nodes accounting for 44174.92kB, 93.50% of 47247.81kB total
Showing top 10 nodes out of 114
flat flat% sum% cum cum%
35842.64kB 75.86% 75.86% 35842.64kB 75.86% myfuncA
1825.78kB 3.86% 79.73% 1825.78kB 3.86% github.com/mozillazg/go-pinyin.init
1805.17kB 3.82% 83.55% 2354.01kB 4.98% compress/flate.NewWriter
1024.14kB 2.17% 85.71% 2048.25kB 4.34% database/sql.(*DB).prepareDC
1024.08kB 2.17% 87.88% 1024.08kB 2.17% net.(*file).getLineFromData
561.50kB 1.19% 89.07% 561.50kB 1.19% html.populateMaps
548.84kB 1.16% 90.23% 548.84kB 1.16% compress/flate.(*compressor).initDeflate
516.76kB 1.09% 91.32% 516.76kB 1.09% net/http.(*http2Framer).WriteDataPadded
513.31kB 1.09% 92.41% 513.31kB 1.09% regexp.onePassCopy
512.69kB 1.09% 93.50% 512.69kB 1.09% vendor/golang.org/x/net/http2/hpack.(*headerFieldTable).addEntry
File: binary
Type: inuse_space
Time: Feb 27, 2020 at 5:58pm (CST)
(pprof) top
Showing nodes accounting for 80.65MB, 83.62% of 96.45MB total
Showing top 10 nodes out of 145
flat flat% sum% cum cum%
35MB 36.29% 36.29% 35MB 36.29% myfuncA
8.50MB 8.81% 45.10% 11MB 11.41% github.com/lib/pq.parseStatementRowDescribe
7.05MB 7.31% 52.42% 7.05MB 7.31% database/sql.(*DB).addDepLocked
6MB 6.22% 58.64% 6MB 6.22% encoding/json.(*decodeState).literalStore
5MB 5.18% 63.82% 19.50MB 20.22% github.com/lib/pq.(*conn).prepareTo
4.59MB 4.76% 68.58% 4.59MB 4.76% reflect.unsafe_NewArray
4.50MB 4.67% 73.25% 11MB 11.41% queryfuncB
4MB 4.15% 77.40% 18.56MB 19.24% database/sql.(*DB).prepareDC
3.50MB 3.63% 81.03% 3.50MB 3.63% github.com/lib/pq.decideColumnFormats
使用 top 可以查看持有内存最多的几个函数并进行排序,通过比对持有最多内存的函数,发现尽管 myfuncA 持有了很多内存,但是两个时间点的 myfuncA 产生的内存都没有变化,而总的内存占用从 47M 上升到了 96M,因此可以排除 myfuncA 泄露的嫌疑。但值得注意的是,这段时间多出来的 50M 也不全是因为内存的泄露,DB 查询时的反序列化也需要申请较多内存,根据 Go runtime 内存分配的策略,GC 并不会立即回收这些内存,即便回收也不会很快将闲置的内存归还给OS,在一段时间内这些内存依然会存在于内存分配器的多级内存池中。因此这其中依然存在着一些阻碍我们分析的干扰项。顺带提一下 reflect.unsafe_NewArray 这个函数,之前看到有人在怀疑它会导致内存泄露,事实上只要是 json 反序列化一个 slice 都会使用它来申请内存,它的上层是 reflect.MakeSlice ,可以根据反射得到的 type 类型信息来创建 slice ,可以理解为通用 slice 的构造函数。
对比两个快照之间的差异
仅仅是通过肉眼查看两个快照之间的差异还是存在蛮多的干扰的,如果能够以第一个时间点为基准看与第二个时间点 diff 过后的结果可能会更加清晰一些。
go tool pprof -base pprof.binary.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz pprof.binary.alloc_objects.alloc_space.inuse_objects.inuse_space.002.pb.gz
File: binary
Type: inuse_space
Time: Feb 27, 2020 at 12:06pm (CST)
(pprof) top
Showing nodes accounting for 37.65MB, 76.19% of 49.42MB total
Dropped 1 node (cum <= 0.25MB)
Showing top 10 nodes out of 118
flat flat% sum% cum cum%
6.50MB 13.16% 13.16% 9MB 18.21% github.com/lib/pq.parseStatementRowDescribe
5.05MB 10.23% 23.38% 5.05MB 10.23% database/sql.(*DB).addDepLocked
5MB 10.12% 33.50% 5MB 10.12% encoding/json.(*decodeState).literalStore
4.58MB 9.28% 42.78% 4.58MB 9.28% reflect.unsafe_NewArray
4MB 8.10% 50.87% 8MB 16.19% funcB (callByA)
4MB 8.10% 58.97% 16MB 32.38% github.com/lib/pq.(*conn).prepareTo
3MB 6.07% 65.04% 3MB 6.07% github.com/lib/pq.decideColumnFormats
2.50MB 5.06% 70.10% 2.50MB 5.06% github.com/lib/pq.(*readBuf).string
1.51MB 3.05% 73.15% 1.51MB 3.05% github.com/lib/pq.textDecode
1.50MB 3.04% 76.19% 39.10MB 79.12% ctrlfuncA
通过 -base 指定基准,再次使用 top 可以准确地列出这多出来的 50M 究竟是何人所为。把这些列出来的方法进行简单的分类:funcA是控制器函数,而 funcB 是 M 层的方法,被A调用并与 postgresql 直接打交道获取数据,其余的有反序列化含有 json 数据字段的标准库函数,最后还有一些与数据库连接相关的函数。初步可以确定的是,内存泄露一定存在于这个方法调用链中的某一步。
在交互式命令行通过 list 方法名 可以一步步深入分析方法调用链上具体的占用情况,排除掉反序列化对象分配内存的干扰,并结合快照2的占用情况。定位到 *DB 和 *conn 这两个对象上,方法调用定位到 sqlx 提供的 Preparex 方法以及 Preparex 产生的 Stmt 对象的 Get 方法。
func (r repoXXX) FindByID(id string) (*T, err) {
stmt, err := r.Preparex(`MY SQL QUERY`) // ???
if err != nil {
return nil, err
}
t := new(T)
err = stmt.Get(t, id) // ???
if err != nil {
if err == sql.ErrNoRows {
return nil, errno.TorNotFound
}
return nil, err
}
return t, nil
}
找到元凶
sqlx 只是 database/sql 的简单包装库,要想知道找到的这两个方法究竟做了些什么,还得从 database/sql 开始说起。
DB 创建
func Open(driverName, dataSourceName string) (*DB, error) {
// 检查数据库驱动是否已经初始化
driversMu.RLock()
driveri, ok := drivers[driverName]
driversMu.RUnlock()
// 没有初始化,报错
if !ok {
return nil, fmt.Errorf("sql: unknown driver %q (forgotten import?)", driverName)
}
if driverCtx, ok := driveri.(driver.DriverContext); ok {
// 通过URI传入连接数据库的配置信息
connector, err := driverCtx.OpenConnector(dataSourceName)
if err != nil {
return nil, err
}
// 初始化 DB 对象并返回
return OpenDB(connector), nil
}
// 默认 connector
return OpenDB(dsnConnector{dsn: dataSourceName, driver: driveri}), nil
}
OpenDB() 显然是 DB 的构造函数,继续往下看
func OpenDB(c driver.Connector) *DB {
ctx, cancel := context.WithCancel(context.Background())
db := &DB{
connector: c,
openerCh: make(chan struct{}, connectionRequestQueueSize),
resetterCh: make(chan *driverConn, 50),
lastPut: make(map[*driverConn]string),
connRequests: make(map[uint64]chan connRequest),
stop: cancel,
}
go db.connectionOpener(ctx)
go db.connectionResetter(ctx)
return db
}
几个关键的组成部分:
openerCh 用于缓存创建新连接的请求,表意单一并且符合先进先出的逻辑,定义成chan struct 再好不过了
resetterCh 用于异步重置连接的 context 并返回当前连接执行 query 的 error
使用了两个 G 异步执行上述的两个操作
lastPut 用于 debug ,跳过
connRequests 用于无闲置数据库连接且无法再创建新连接时的异步请求排队,key是递增的,value 使用 chan 防止读取阻塞,len可以非常方便地计数
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
// ...
// 发现有请求在排队
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
delete(db.connRequests, reqKey) // 排队队列中取出=
if err == nil {
dc.inUse = true
}
// 为这个请求分配连接
req <- connRequest{
conn: dc, // *driverConn 即数据库连接
err: err,
}
return true
}
}
目前我们可以得知, connRequest 代表创建新连接的请求,connRequests 用于全局的请求排队,每当有创建新连接的请求时,DB 会尝试重用可用的 driverConn以满足这些请求,注意这些请求不是 query 请求,而是创建连接的请求
记录资源的依赖引用
DB对象的 conn 方法负责获取连接,有连接了,才能将我们的语句发送到数据库,以 SELECT 语句的查询为例
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
// 获取连接或者失败返回错误
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
// 熟悉的 stmt, Rows 对象是从这里创建,绑定driverConn执行然后被返回的
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}
先不要跑太远,毕竟我们并不是使用这种方法访问数据库,但是上面的调用可以帮助理清标准库是如何组织这些底层对象的。现在回到 sqlx 的 preparex 方法,这里是我们问题的开始,最终调用的还是标准库 DB 的 PrepareContext 方法
func (db *DB) PrepareContext(ctx context.Context, query string) (*Stmt, error) {
var stmt *Stmt
var err error
// 约定一个失败重试次数,使用标志位控制获取连接的策略(优先使用缓存的连接)
for i := 0; i < maxBadConnRetries; i++ {
stmt, err = db.prepare(ctx, query, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.prepare(ctx, query, alwaysNewConn)
}
return stmt, err
}
func (db *DB) prepare(ctx context.Context, query string, strategy connReuseStrategy) (*Stmt, error) {
// 同样尝试获取连接或者失败返回
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.prepareDC(ctx, dc, dc.releaseConn, nil, query)
}
这里的 prepare 和前面提到的 query 方法非常相似,后面我们再详谈它们的区别,这里我们接着 prepareDC 这条线索继续往下探索。
// cg 为 nil 表示启用连接池!(手动画重点)
func (db *DB) prepareDC(ctx context.Context, dc *driverConn, release func(error), cg stmtConnGrabber, query string) (*Stmt, error) {
var ds *driverStmt
var err error
defer func() {
release(err)
}()
withLock(dc, func() {
ds, err = dc.prepareLocked(ctx, cg, query)
})
if err != nil {
return nil, err
}
stmt := &Stmt{
db: db,
query: query,
cg: cg,
cgds: ds,
}
// 这部分才是 preparex 的真实目的,使用连接池
if cg == nil {
// prepare 事先将得到的连接和语句保存起来
stmt.css = []connStmt{{dc, ds}}
// 记录当前已关闭连接的总数,清理已关闭的连接时会用到
stmt.lastNumClosed = atomic.LoadUint64(&db.numClosed)
// 添加依赖引用计数(目前来看不太清楚是干什么用),但是stmt肯定被持有
db.addDep(stmt, stmt)
}
return stmt, nil
}
其中返回的 stmt 就是 Preparex 的所得产物,然后执行了 Get,经过 sqlx 的包装,最终调用的还是标准库中的func (s *Stmt) QueryContext,和 sqlx 中的 func (r *Row) scanAny
可以肯定的是,在调用 Preparex 后,stmt 引用已经被 db 持有,只要 db 对象一直存在,stmt 想要被释放,就必须有对应的代码手动解除 stmt 的引用,简要的看看 QueryContext,是否有我们想要的类似 removeDep 的操作
func (s *Stmt) QueryContext(ctx context.Context, args ...interface{}) (*Rows, error) {
// ...
rowsi, err = rowsiFromStatement(ctx, dc.ci, ds, args...)
if err == nil {
rows := &Rows{
dc: dc,
rowsi: rowsi,
}
s.db.addDep(s, rows) // HERE
rows.releaseConn = func(err error) {
releaseConn(err)
s.db.removeDep(s, rows) // HERE
}
var txctx context.Context
if s.cg != nil {
txctx = s.cg.txCtx()
}
rows.initContextClose(ctx, txctx)
return rows, nil
}
releaseConn(err)
}
有,但这些是关于 rows 的引用记录以及数据库连接的重用的代码,并没有看到 stmt 对象的释放,同样翻看 sqlx 的 scanAny,主要是将数据库返回的数据通过调用 Scan 序列化到传入 Get 的结构体具体字段中。
上述发现证实了本次内存泄露的元凶:db.dep,即用于引用计数从而保证依赖先行释放的字典,这个字典保证了只有元素的依赖被释放后当前元素才能释放,调用当前元素的 finalClose 方法自行释放当前元素持有的资源。
解决泄露
因此想要解决这次的内存泄露,就必须让 dep 放弃对 stmt 的引用。通过对 sql.go 文件的简单搜索,stmt 对象的释放就藏在它的 close 方法中。
func (s *Stmt) Close() error {
// ...
if s.cg == nil {
return s.db.removeDep(s, s) // 真正释放了stmt,不再持有其引用
}
}
一行代码就能解决了
stmt, _ := r.Preparex(`MY SQL QUERY`)
// 这句必不可少!!
defer stmt.Close()
// ...
重新部署,并对内存使用情况进行采样,结果如下图所示:
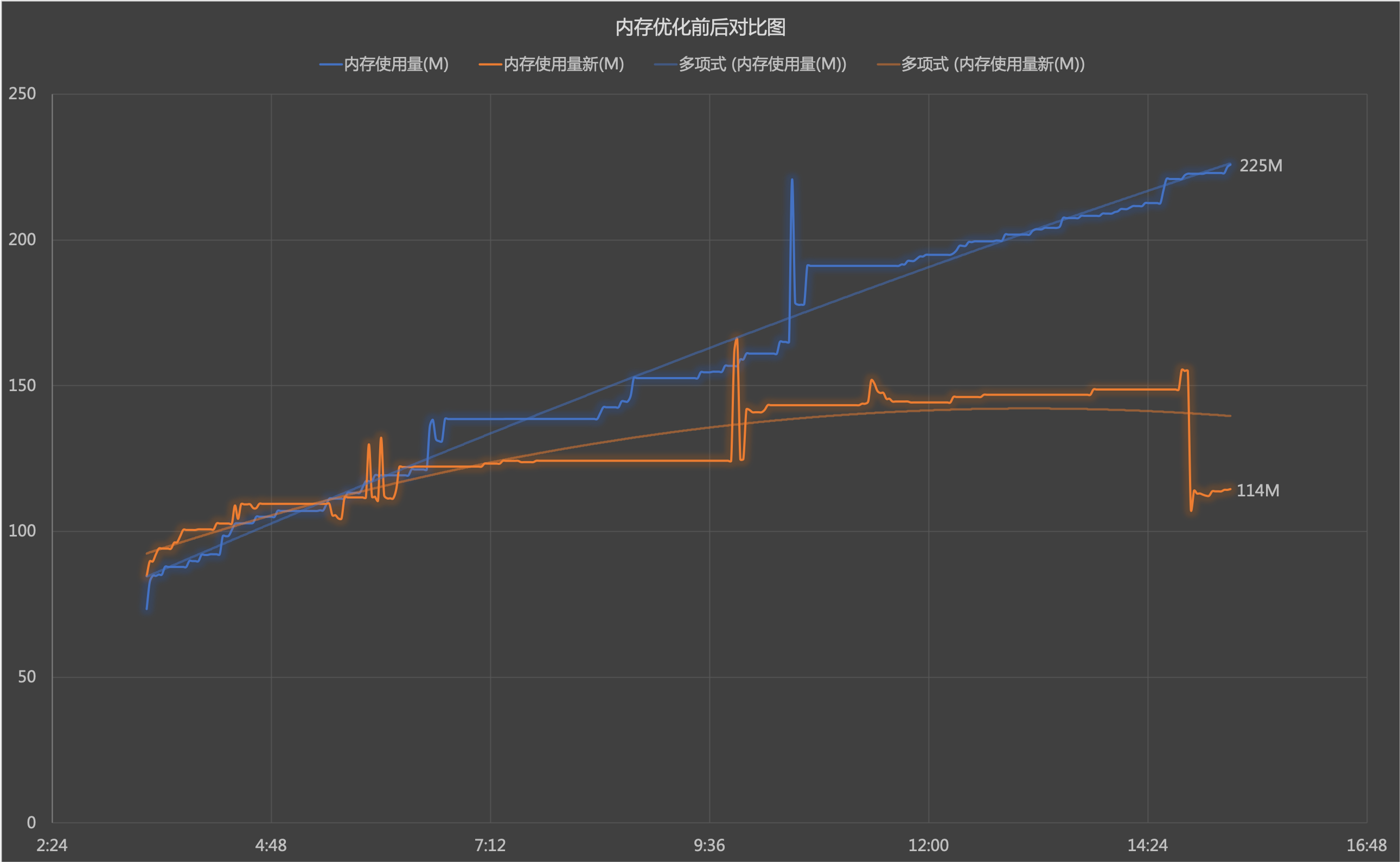
GC 能够正常地回收 stmt 对象,问题解决!
总结
得到的教训:
- 前期:做 load test,能在线下解决就别放到线上;善用 pprof;写好文档,避免他人踩坑
- 上线:监控和报警要做到位,内存占用超过了一定阈值必须引起重视,善用
http/pprof - 平时:多熟悉平时重度使用的包和标准库,尤其是标准库,其中隐藏了很多的细节,稍不留神就踩坑
其他潜在的泄露(彩蛋)
说实话,这并不是我在 Go 中遇到的第一次内存泄露,但 Go 确实没那么容易出现这类问题,通过我的多次踩坑反思,我发现一些 G 导致的内存泄露其实通过 pprof 或者监控是能够很快得到解决的,反而是长期被持有的引用很容易被忽视掉,这些泄露的苗头常常会出现在:
- 手动维护的对象池
- 手动控制的系统资源:如定时器,连接,IO缓冲流等
- 默认无上限的数值限制:如db.maxOpen
